ADAS巨卷干货,你能拿到
点击进入→自动驾驶之心【模型部署】技术交流群
后台回复【CUDA】获取CUDA实战书籍!
CUDA 内存模型
CUDA中的可编程存储器类型有:
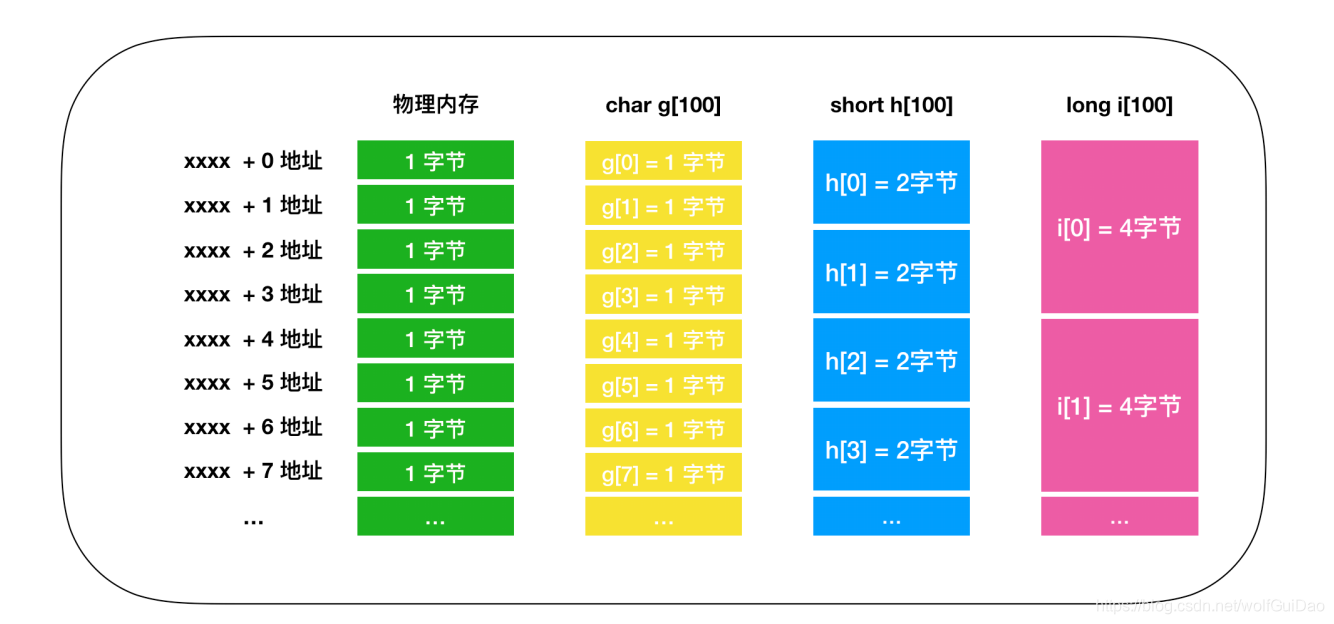
这些内存空间的层次结构如下图所示,每种不同类型的内存空间都有不同的作用域、生命周期和缓存行为。在内核函数中,每个线程都有自己的本地内存,每个线程块都有自己的共享内存并且对块内的所有线程可见,线程网格中的所有线程都可以访问全局内存、常量内存和纹理内存,其中常量内存和纹理内存是只读内存空间。
如果对线程和线程块的概念不熟悉,可以参考之前的文章
CUDA Programming-03:线程级寄存器
在没有其他修饰符的内核函数中声明的变量通常存储在 GPU 寄存器中,例如下面代码中的线程索引变量 i。寄存器通常用于存储内核函数中需要经常访问的线程私有变量。这些变量具有与核函数相同的生命周期。内核函数执行后,就不能再访问了。
__global__?void?VectorAddGPU(const?float?*const?a,?const?float?*const?b,
?????????????????????????????float?*const?c,?const?int?n)?{
??int?i?=?blockDim.x?*?blockIdx.x?+?threadIdx.x;?
??if?(i?<?n)?{
????c[i]?=?a[i]?+?b[i];?
??}
}寄存器是 GPU 中最快的内存空间,但一个 SM 中的寄存器数量相对有限。一旦内核函数使用的寄存器数量超过硬件限制,就会使用本地内存来替换占用较多的寄存器。这种寄存器溢出的情况会带来不利的性能影响,我们在实际编程过程中应该避免这种情况。使用 nvcc 编译选项 maxrregcount 来控制内核函数使用的最大寄存器数:
-maxrregcount=32
本地内存
在内核函数中,存储在寄存器中但无法进入分配的寄存器空间的变量将被溢出到本地内存中。可以存储在本地内存中的变量有:
溢出到本地内存中的变量与全局内存本质上是相同的区域。
共享内存
内核函数中用 __shared__ 修饰符修饰的变量存储在共享内存中。每个 SM 都有一定数量的由线程块分配的共享内存。它们在内核函数中声明。生命周期伴随着整个线程块。线程块执行完成后,分配给它的共享内存也被释放,重新分配给其他线程块使用。线程块中的线程可以通过使用共享内存中的数据相互协作,但是在使用共享内存时,必须调用以下函数进行同步:
void?__sybcthreads()该函数为线程块中的所有线程设置了一个执行屏障点,使得同一个线程块中的所有线程必须执行到这个屏障点才能down掉,这样可以避免一些潜在的数据冲突。
持续记忆
常量变量用 __constant__ 修饰符修饰寄存器传输级,它们必须在全局空间和所有内核函数之外声明,并且对同一编译单元中的内核函数可见。常量变量存储在常量内存中,内核函数只能从常量内存中读取数据。必须使用以下函数在主机端代码中初始化常量内存:
cudaError_t?cudaMemcpyToSymbol(const?void*?symbol,?const?void*?src,size_t?count);下面的例子展示了如何声明常量内存并与之交换数据:
__constant__?float?const_data[256];
float?data[256];
cudaMemcpyToSymbol(const_data,?data,?sizeof(data));
cudaMemcpyFromSymbol(data,?const_data,?sizeof(data));常量内存适用于warp中所有线程都需要从同一个内存地址读取数据的情况,比如所有线程都需要常量参数,每个GPU只能声明不超过64KB的常量内存。
全局内存
全局内存是GPU中容量最大、延迟最高的内存空间,其作用域和生命空间是全局的。全局内存变量可以使用 cudaMalloc 函数在主机代码中动态声明,也可以使用 __device__ 修饰符在设备代码中静态声明。全局内存变量可以在任何 SM 设备中访问,它们的生命周期贯穿应用程序的整个生命周期。

下面的例子展示了如何静态声明和使用全局变量:
#include?
#include?
__device__?float?dev_data;
__global__?void?AddGlobalVariable(void)?{
??printf("device,?global?variable?before?add:?%.2fn",?dev_data);
??dev_data?+=?2.0f;
??printf("device,?global?variable?after?add:?%.2fn",?dev_data);
}
int?main(void)?{
??float?host_data?=?4.0f;
??cudaMemcpyToSymbol(dev_data,?&host_data,?sizeof(float));
??printf("host,?copy?%.2f?to?global?variablen",?host_data);
??AddGlobalVariable<<<1,?1>>>();
??cudaMemcpyFromSymbol(&host_data,?dev_data,?sizeof(float));

??printf("host,?get?%.2f?from?global?variablen",?host_data);
??cudaDeviceReset();
??return?0;
} 上面代码中需要注意的是,变量dev_data只是作为标识符存在,而不是设备端全局内存变量的地址,所以不能直接使用cudaMemcpy函数将主机上的数据拷贝到设备端. 不能直接在主机端的代码中使用运算符&来取设备端变量的地址,因为它只是一个代表设备端物理位置的符号,但是我们可以使用下面的函数来获取它的地址:
cudaError_t?cudaGetSymbolAddress(void**?devPtr,?const?void*?symbol);该函数用于获取设备端全局内存的物理地址。获取地址后,可以使用cudaMemcpy函数进行操作:
int?main(void)?{
??float?host_data?=?4.0f;
??float?*dev_ptr?=?NULL;
??cudaGetSymbolAddress((void?**)&dev_ptr,?dev_data);
??cudaMemcpy(dev_ptr,?&host_data,?sizeof(float),?cudaMemcpyHostToDevice);
??printf("host,?copy?%.2f?to?global?variablen",?host_data);
??AddGlobalVariable<<<1,?1>>>();
??cudaMemcpy(&host_data,?dev_ptr,?sizeof(float),?cudaMemcpyDeviceToHost);
??printf("host,?get?%.2f?from?global?variablen",?host_data);
??cudaDeviceReset();
??return?0;
}程序的输出如下:
host, copy 4.00 to global variable
device, global variable before add: 4.00
device, global variable after add: 6.00
host, get 6.00 from global variable在CUDA编程中,一般情况下,设备端的内核函数不能访问主机端声明的变量,而主机端的函数也不能直接访问设备端的变量,即使它们声明在同一个文件中。
纹理记忆
纹理内存驻留在设备内存中,并缓存在每个 SM 的只读缓存中。纹理内存是通过指定的只读缓存访问的全局内存,它优化了二维空间的局部性寄存器传输级,因此使用纹理内存访问二维数据的线程可以达到最佳性能。
缓存
GPU上有4种缓存:
每个 SM 都有一个 L1 缓存,所有 SM 共享一个 L2 缓存,每个 SM 只有一个只读常量缓存和一个只读纹理缓存。L1和L2缓存用于在本地内存和全局内存中存储数据,包括寄存器溢出的部分。
固定记忆
默认的主机端内存是可分页的,它将主机虚拟内存上的数据移动到操作系统需要的不同物理位置。GPU 无法安全地访问可分页主机端内存上的数据,因为它无法控制主机端操作系统何时跨物理位置移动该数据。在将数据从可分页主机端内存传输到设备端内存时,CUDA驱动会先临时分配页锁定或固定的主机端内存,然后将主机端数据复制到内存中,最后从记忆。数据被复制到设备端的内存中。
CUDA 提供以下函数来直接分配固定的主机内存:
cudaError_t?cudaMallocHost(void?**devPtr,?size_t?count);这样分配的主机端固定内存可以直接被设备端访问,从而使设备端可以进行高带宽的读写操作。但是,分配过多的固定内存会降低主机系统的性能,因为可用于虚拟内存的可分页内存较少。固定内存必须由以下函数释放:

cudaError_t?cudaFreeHost(void?*ptr);零拷贝内存
如前所述,一般情况下,主机无法直接访问设备端的变量,设备也无法直接访问主机端的变量。有一个例外,就是零拷贝内存,主机和设备都可以访问零拷贝内存。在内核函数中使用零拷贝内存有几个优点:
零拷贝内存是固定内存。CUDA 提供以下函数来创建固定内存到设备地址空间的映射:
cudaError_t?cudaHostAlloc(void?**pHost,?size_t?count,?unsigned?int?flags);flags 参数可以从以下选项中选择
使用以下函数获取映射到固定内存的设备端指针:
cudaError_t?cudaHostGetDevicePointer(void?**pDevice,?void?*pHost,?unsigned?int?flags);该函数得到的指针pDevice可以在设备上引用,访问映射得到的主机端的固定内存。
如果需要在主机和设备之间共享少量数据,零拷贝内存可能是一个不错的选择。但是对于需要频繁读写的操作,使用零拷贝内存会显着降低程序的性能,因为每次映射到内存的传输都需要经过PCIe总线。此外,使用零拷贝内存必须同步主机和设备内存访问,以避免潜在的数据冲突。
参考
【自动驾驶之心】全栈技术交流群
Autopilot Heart是第一个自动驾驶开发者社区,专注于物体检测、语义分割、全景分割、实例分割、关键点检测、车道线、物体跟踪、3D物体检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精度地图、规划控制、模型部署与落地、自动驾驶模拟测试、硬件配置、AI求职交流等;
加入我们:自动驾驶心脏技术交流群总结!
自动驾驶的核心【知识星球】
想了解更多关于自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位与建图(SLAM、高-精密地图)、自动驾驶规划与控制、现场技术解决方案、AI模型部署与实战、行业动态、招聘信息,欢迎扫描下方二维码加入自动驾驶心脏知识星球(三天内无条件退款),每日分享论文+代码,这里汇聚了产学界大佬,前沿技术方向尽在掌握,期待交流!